
The Implementation Path
From Framework to Reality

Governed by Design - Edition 6
This is the sixth and final edition of a six-part series on AI agent governance. Each edition has introduced a named primitive and a downloadable resource. This one closes the arc.
A team has finished reading the first five editions of this series.
They have the vocabulary now. Governance Maturity Gap. Decision Boundary Contract. Oversight Spectrum. Accountability Canvas. Handoff Receipt. Five primitives. A way of talking about agent governance that didn’t exist for them five weeks ago.
Then comes the question we keep getting:
Where do we actually start?
That question is what this edition is for.
A short bridge from Edition 5
Last week’s piece introduced the proof layer, Handoff Receipts as the unit of evidence at the agent layer, signed and chained, generated automatically at every transition.
Five primitives are now on the table. Each one answers a question that stalls agent projects in regulated environments:
Are we ready? Governance Maturity Gap (Edition 1)
What is the agent allowed to do? Decision Boundary Contract (Edition 2)
When does a human enter? Oversight Spectrum (Edition 3)
Who is accountable? Accountability Canvas (Edition 4)
What did the agent actually do, and why? Handoff Receipt (Edition 5)
That’s the framework. This edition is about how it becomes real.
The transformation-program trap
Most attempts at AI governance fail in a specific way.
Someone reads a framework. The framework is good. Someone proposes a transformation program, a steering committee, a governance charter, a multi-quarter rollout, a vendor selection cycle. The proposal lands in front of an executive. The executive looks at the headcount and the timeline.
The program never gets approved. Or it gets approved at half the scope and stalls at month four. Meanwhile, the agent projects keep launching. The boundaries remain implicit. The audit trails remain reconstructed after the fact.
Governance loses to deployment because deployment moves and governance proposes.
This is the pattern Forrester’s 2026 Enterprise AI Survey caught in its “71% lack formal governance” finding. It’s also what Gartner’s “Governing Agentic AI” research is pointing at when it notes that organizations miss 60–70% of agent-specific risk vectors. The gap isn’t a knowledge problem, the frameworks exist. It’s an architecture-of-action problem. The work isn’t packaged in a way teams can ship.
The implementation path is a different starting position. It treats governance as a sequence of small, specific deliverables, each one producing something that didn’t exist before. No transformation program required.
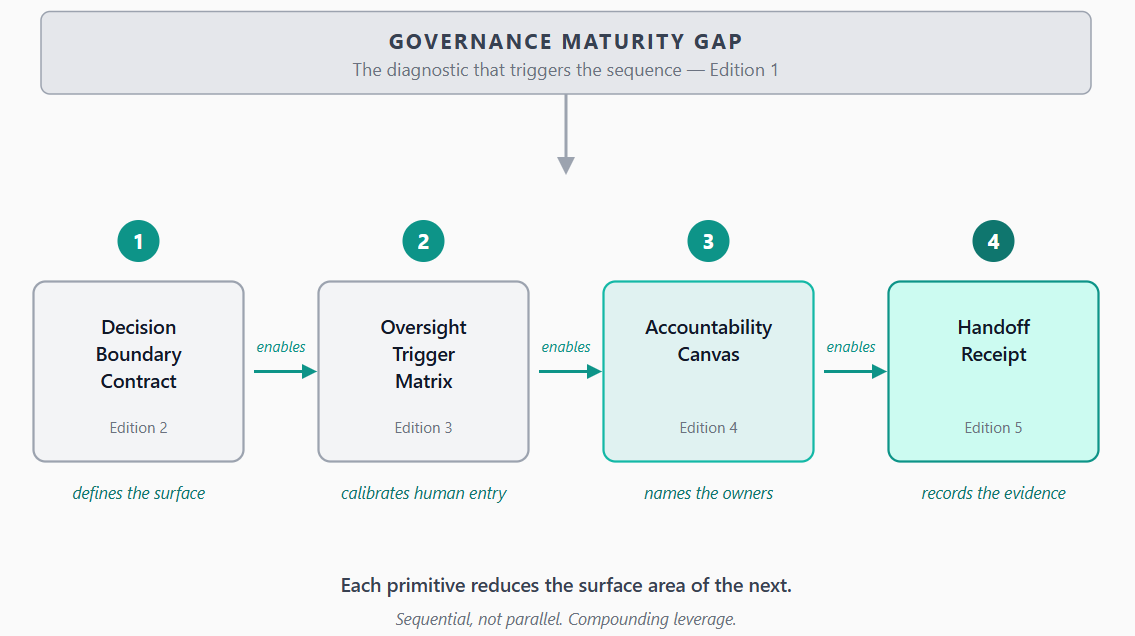
The compounding sequence
The five primitives don’t have to be deployed all at once.
They compound. Each one reduces the surface area of the next.
When the Decision Boundary Contract is written, the Oversight Trigger Matrix has something concrete to reference. When the Trigger Matrix is operational, the Accountability Canvas has actual handoff points to assign owners to. When ownership is assigned, the Handoff Receipt knows what to record.
Sequential, not parallel.
This matters because the version that fails is the one that tries to do all five at once and ends up doing none of them well. The version that works picks the first move, ships it, then uses the artifact to constrain and accelerate the next move.
The Compounding Sequence
Move 1: The Boundary Contract
The first move is always the Decision Boundary Contract.
Not because it’s most important. Because it’s the constraint that shapes everything that follows.
Until we know what the agent is allowed to decide and where its authority ends, we can’t write the trigger matrix that governs human entry. We can’t name the owner who’s accountable for each decision. We can’t define which transitions deserve a receipt. The boundary is the artifact every other primitive references.
Teams that skip this and go straight to oversight design or audit logging tend to drift. The oversight rules can’t anchor to anything specific. The audit logs capture the wrong events because there’s no agreement on what events matter.
The right scope for the first contract: one agent, one bounded use case, one document. Machine-readable in a structured format the team can already parse and enforce, JSON or YAML against a schema is sufficient. Versioned from day one. Reviewed by Compliance and the AI Lead jointly.
Concrete example. A payments-firm fraud-flagging agent. The boundary contract specifies that the agent may flag transactions for review when its confidence score exceeds a defined threshold, but it may not freeze accounts, may not contact customers, and may not modify the customer record. Each of those constraints is a structured rule, not a sentence in a policy PDF.
That’s the leverage point. From here, the next three moves get cheaper.
Move 2: The Trigger Matrix
The second move is the Oversight Trigger Matrix, and it’s smaller than most teams expect.
Not a full intervention framework. Not an approval-queue redesign. A short document that lists the conditions under which a human is brought in, written in the same language as the boundary contract.
The matrix doesn’t have to cover every edge case. It has to cover the edges that matter, the high-impact, low-reversibility, regulator-visible ones. The rest can default to autonomous and be revisited as patterns emerge.
For the fraud-flagging agent: the matrix specifies that any transaction above a defined value threshold routes to a human reviewer regardless of confidence score, any pattern matching suspected sanctions exposure routes immediately to Compliance, and any agent action that triggers a customer-facing notification routes to the operations queue for a final review. Three triggers. Each one anchored to a specific clause in the boundary contract.
The matrix is intentionally narrow at the start. EU AI Act Article 14 doesn’t require oversight at every transition, it requires proportionate oversight. Calibration is the point.
This is the version of oversight that scales. Narrow at the start. Adjusted as the receipt data comes in. Not the version that adds an approval step to every agent action and then blames the agent for being slow.
Move 3: The Accountability Canvas
The third move is the Accountability Canvas, and it’s a one-page document.
Four roles named pre-deployment: who owns the boundary, who owns the oversight, who owns error response, who owns boundary updates. With named humans, named backups, and a documented rotation protocol.
The canvas doesn’t require a new org chart. It requires a meeting where four names get put on a page before the agent ships. We’ve seen this take less than an hour when the right people are in the room, and absorb a quarter of stalled work when they aren’t.
Article 26 of the EU AI Act is explicit on this point. Deployers must assign human oversight to natural persons with the necessary competence, training, and authority. The canvas operationalizes that requirement at the agent level. It moves oversight from an abstract obligation to a name on a page.
A failure mode worth flagging: the canvas often surfaces internal disagreements about ownership that have been latent for months. That disagreement is productive. Better surfaced now than during an incident.
The canvas turns diffuse responsibility into a small, finite list of names.
Move 4: The Handoff Receipt
The fourth move is the Handoff Receipt, and at the start, it’s lighter than the version Edition 5 described.
The full pattern, signed, chained, tamper-evident, stored outside the agent’s trust boundary, is what it should grow into. The first version is a structured event written at every meaningful transition, capturing the boundary version that was active, the oversight zone that applied, the accountable owner from the canvas, and the action taken.
Three transition types are enough to start: agent decides, agent invokes a tool, agent escalates. Each one generates a receipt. The schema is versioned alongside the boundary contract.
The signing infrastructure can come later. What matters at the start is that the structure exists, the schema is versioned, and the receipts are queryable.
This staging matters because EU AI Act Article 12’s “automatic recording” requirement doesn’t specify cryptographic signing, it requires automatic generation, traceability, and integrity sufficient for evidentiary value. The first version of the receipt schema can satisfy the first two outcomes immediately. Tamper-evidence is added before August 2, 2026.
This is where governance starts to feel less like documentation and more like memory.
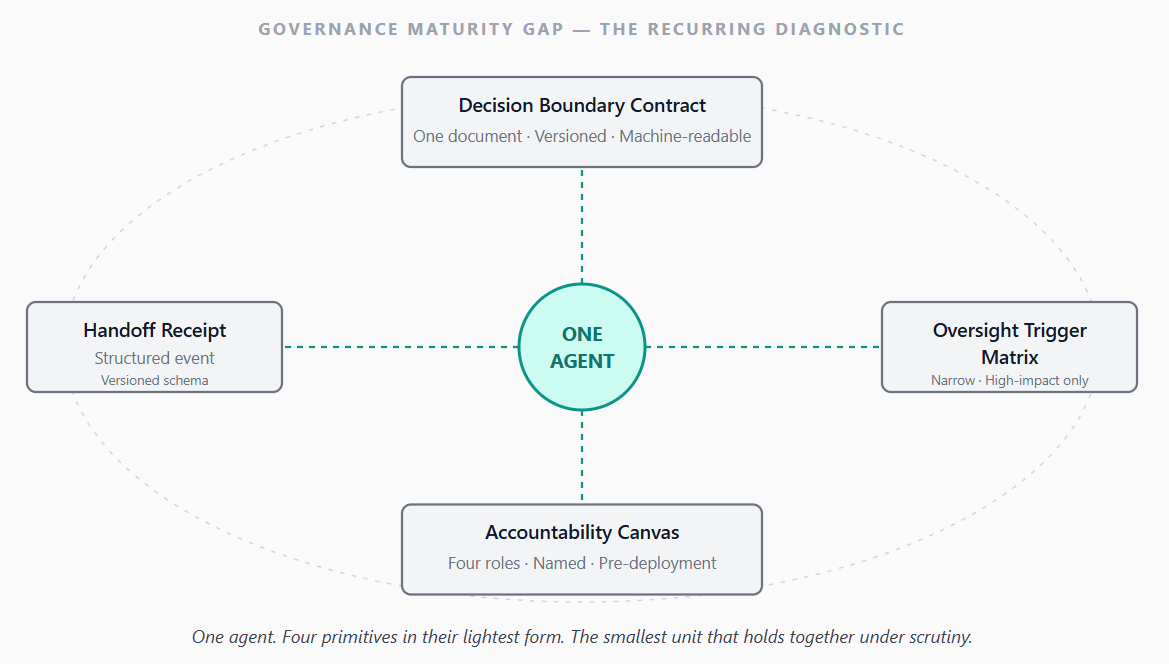
The Minimum Viable Governance Unit
The three traps
Three failure modes recur across organizations attempting this work. They’re worth naming because they’re easier to refuse than to recover from.
The policy-document trap. A long governance policy gets written, circulated, and signed. None of it is machine-readable. None of it constrains the agent at runtime. The document satisfies an audit reviewer who doesn’t ask the next question. It does not satisfy a regulator who does. The fix isn’t a better policy. It’s a structured boundary contract attached to a specific agent.
The platform-first trap. A team decides governance starts with selecting the right platform, vendor evaluation, RFP, procurement cycle. Six months pass. The platform arrives. By then, the agents have been running, and the governance becomes a retrofit on systems already in production. The fix is to build the artifacts before the platform; the platform supports the artifacts, not the other way around.
The perfect-framework trap. A team waits for the canonical standard to land, ISO/IEC 42001 maturity, the EU AI Act technical standards, OWASP’s next revision. The wait is reasonable. It’s also indefinite. Two of the closest standards in flight, prEN 18229-1 and ISO/IEC DIS 24970, are still in draft. They may land after enforcement begins. The fix is to build to the outcomes the regulation requires, keep the schemas versioned, and treat schema migration as a manageable operational task rather than a blocker.
The implementation path doesn’t avoid these traps with discipline. It avoids them by being concrete enough that the traps can’t take hold. One agent. One boundary. One canvas. One receipt schema.
A twelve-week sequence
Between now (May 2026) and August 2, 2026, when EU AI Act Article 26 enforcement begins for high-risk systems, there are roughly twelve weeks. That window maps onto the four moves with realistic pacing.
Weeks 1–2: Decision Boundary Contract. Pick one agent. Draft the contract. Specify allowed actions, forbidden actions, threshold conditions. Review jointly with Compliance and the AI Lead. Version it. Store it where the agent runtime can reference it at execution time.
Week 3: Oversight Trigger Matrix. Define the three to five triggers that route human entry. Anchor each one to a clause in the boundary contract. Decide the routing, who receives each escalation, what their SLA is, what authority they have to override.
Week 4: Accountability Canvas. Run the canvas meeting. Name the four owners. Document the rotation protocol. Get sign-off. Sixty minutes if the right people are in the room; longer if they aren’t, which is itself useful information.
Weeks 5–6: Handoff Receipt schema and pilot integration. Design the receipt schema. Build the middleware that generates a receipt at each transition. Store receipts in an append-only location outside the agent’s trust boundary. Pilot the integration with a small slice of agent traffic.
Weeks 7–8: First agent in production with all four primitives. Monitor. Adjust the trigger matrix where the data shows it’s miscalibrated. Patch the boundary contract when the canvas surfaces edge cases the contract didn’t cover.
Weeks 9–10: Receipt review and calibration. Use the receipt chain to answer specific questions: which conditions were evaluated most often, which oversight zone was active during edge cases, where the canvas’s named owners actually exercised authority. The receipts are now operational memory.
Weeks 11–12: Second agent enters the sequence, faster. Templates exist. The canvas pattern is rehearsed. The receipt schema is reusable. The second agent typically completes the sequence in half the time.
By August 2, the team has two production agents with full governance instrumentation. That’s not transformation. It’s two agents.
Team structure for small teams
The implementation path runs without a governance function. It runs with three roles working in concert.
The Compliance Officer. Owns the canvas. Owns the regulatory translation between the boundary contract and applicable rules (EU AI Act, DORA, sectoral guidance). Signs off on what the contract permits.
The AI / Automation Lead. Owns the boundary contract. Owns the trigger matrix. Translates between the agent’s technical surface and the governance vocabulary.
The Engineer. Owns the receipt infrastructure. Implements the boundary at runtime. Builds the middleware that generates and stores receipts.
That’s three people. They don’t all need to be senior. They do all need to be in the same room, physically or otherwise, for the canvas meeting and for the boundary contract review.
In larger teams, these roles can each be played by a small group. In very small teams, two people can hold all three responsibilities, with deliberate rotation to prevent single-point dependency.
The point is that the implementation path is sized for the teams who actually own the agents, not for a separate governance function added on top of them.
Common objections
Four objections come up consistently. Each one has a shorter answer than it looks.
“We need executive sponsorship before we can start.” The implementation path runs at one-agent scope. It doesn’t require executive sponsorship, it requires a Compliance Officer, an AI Lead, and an Engineer who agree to spend twelve weeks on a specific deployment. Sponsorship is what comes when the second and third agents follow the same pattern, not what’s required for the first.
“We need to select a governance platform first.” The boundary contract, the trigger matrix, the canvas, and the first version of the receipt schema can all be implemented with tools the team already has. Platforms add leverage later. They don’t gate the first move.
“We need legal sign-off on the framework.” Legal sign-off on one boundary contract for one agent is faster than legal review of a generic framework. The contract gives Legal something specific to react to. The framework gives Legal something abstract to debate.
“We need the technical standards to land first.” The technical standards may land after enforcement begins. The regulation is already binding. Build to the outcomes the regulation specifies, keep the schemas versioned, and treat standards-driven migration as an operational task that the receipt infrastructure makes manageable.
The pattern across these four is the same: the objections frame the work as something that requires a precondition. The implementation path treats the work itself as the precondition.
The regulatory window
The calendar is the reason this matters now.
EU AI Act Article 26 enforcement for high-risk AI systems begins August 2, 2026. Article 12’s automatic logging requirement is part of that wave. Tier 2 penalties for record-keeping failures run up to €15 million or 3% of worldwide turnover. The Commission’s Digital Omnibus package has proposed phasing some elements out to 2027, with trilogues currently underway, but the binding date remains August until those proposals are adopted.
DORA is already live. Its four-hour incident reporting timeline has been enforceable across the EU financial sector since January 2025. Major ICT incidents involving agent systems now fall under that timeline by default.
The teams that are ready in August are not the teams that started a transformation program in May. They’re the teams that shipped the first concrete artifact in May, the second in June, the third in July.
The window is open. It’s also finite.
The series, closed
The thesis at the start of Edition 1 was that governance maturity is the hidden bottleneck, that organizations stall not because the technology isn’t ready, but because the structure isn’t.
Five editions later, the thesis hasn’t changed. What’s changed is that the structure is now nameable.
The Governance Maturity Gap is the diagnostic that surfaces the bottleneck.
Decision Boundary Contracts make agent authority machine-readable.
The Oversight Spectrum makes human entry calibrated, not reflexive.
The Accountability Canvas turns diffuse responsibility into named roles.
Handoff Receipts make the agent’s behavior queryable, not reconstructed.
The Implementation Path is how the other five become real.
Five primitives. One sequence. One agent at a time.
The version of governance we keep arguing for isn’t a program. It’s a property of the architecture. A team that has built one boundary contract has more governance than a team with a hundred-page policy. A team that runs one accountability canvas has more clarity than a team with a steering committee. A team that produces one signed receipt has more evidence than a team with a year of unstructured logs.
This is what we mean by governed by design. Not governance as something you launch. Governance as something the system has, because it was built that way.
For now, the question we’re sitting with as we close the series:
Before August 2, 2026, which agent in our environment will be the first one we ship with all five primitives in place?
If governance is the architecture of trust, the implementation path is how that architecture gets built.
One decision at a time.
Your resource: Governed by Design Implementation Playbook
The downloadable for this edition aggregates the full series into a single working document.
It includes:
Pre-Deployment Governance Checklist: the five conditions from Edition 1, formatted as a self-assessment
Decision Boundary Contract template: schema with worked example, from Edition 2
Oversight Trigger Matrix template: risk × intervention grid, from Edition 3
Accountability Canvas: one page, four roles, rotation protocol, from Edition 4
Agent Audit Schema Template: receipt fields and tamper-evidence design, from Edition 5
The twelve-week sequencing checklist: week-by-week deliverables and decision points
Download it here:
Use it to scope the first agent, to assess an agent already in production, to start the conversation in your organization about which deployment is the first one to take all five primitives seriously.
🎧 Prefer listening? This edition is available as a podcast:
Spotify:
Apple Podcasts:
Series complete. Six editions. Five primitives. One implementation path.
Thank you for reading along. The work continues.
A note on scope
This piece is general commentary on AI governance design, not legal advice. For authoritative regulatory text, consult Regulation (EU) 2024/1689 (the EU AI Act) and Regulation (EU) 2022/2554 (DORA), along with applicable national implementing rules and competent-authority guidance. Where regulatory interpretation is consequential to your organization, consult qualified counsel.
References
EU AI Act, Article 12 (Record-Keeping for High-Risk AI Systems)
EU AI Act, Article 14 (Human Oversight, proportionate oversight requirement)
EU AI Act, Article 26 (Deployer Obligations, applicable from 2 August 2026)
EU AI Act, Article 99 (Tiered Penalty Structure, Tier 2 up to €15M / 3% turnover)
EU AI Act, Article 113 (Phased Application timeline)
Digital Omnibus package proposal (November 2025; trilogue negotiations underway)
DORA (Regulation (EU) 2022/2554), Articles 17–19, in force across the EU financial sector since January 2025
DORA Regulatory Technical Standards on incident reporting timelines (4h initial / 72h intermediate / 1 month final)
ISO/IEC 42001:2023 (AI Management System Standard)
prEN 18229-1 (draft European standard, AI logging and human oversight)
ISO/IEC DIS 24970 (draft international standard, AI system logging)
Forrester, 2026 Enterprise AI Survey (formal governance penetration: 71% gap)
Gartner, Governing Agentic AI (agent-specific risk vector coverage: 60–70% miss rate)
MIT CISR, Operational backbone research
OWASP Top 10 for Agentic Applications 2026